“And this is wisdom and temperance and self-knowledge — for a man to know what he knows, and what he does not know.” - Plato, Charmides
“To say you know when you know, and to say you do not when you do not — that is knowledge.” - Confucius
Special thanks to Yash Sharma for a lot of valuable feedback on my idea and evaluation methodology
Research code: https://github.com/pranavc28/thought-engineering-and-self-awareness
Claim
Thought engineering techniques (overthinking and automated confidence refinement) improve multi-classification performance across all model architectures. The purpose of this blog is to explain these terms, and prove why this is true.
Motivation
Despite the rise of reasoning models, limited research exists on how confident LLMs are in their reasoning processes and whether this confidence can be systematically evaluated through natural language—similar to humans. We term this capability self-awareness. This blog proposes a method for evaluating model self-awareness using natural language confidence scores within responses from LLMs and introduces automated confidence refinement, a novel framework to improve LLM accuracy in multi-classification problems. This represents the first exploration under the broader umbrella that I have termed thought engineering, as the industry releases more powerful thinking models.
We discuss what constitutes self-awareness in LLMs, demonstrate why this capability is critical for providing context based on an LLM’s reasoning, and validate this method’s accuracy using confidence scores for statistical significance.
Definition of Automated Confidence Refinement
Consider a thinking LLM given a multi-classification task (e.g., “Maybe”, “Yes”, or “No”). During its reasoning chain, the model exhibits varying confidence across different steps. We can extract this confidence as numerical scores (0.0-1.0) by prompting for them in natural language.
For steps with low confidence (e.g., <0.5), we can either hardcode an outcome or provide additional context to improve the model’s solution. Automated confidence refinement systematically determines these optimal confidence thresholds per outcome in multi-classification problems. For confidence between 0.5 - 0.75 for example, we can prompt the LLM that it needs to increase the context added, for the purpose of this blog, on its own.
Background
Current LLM reasoning relies on prompting strategies like Chain of Thought (CoT) and ensemble methods that aggregate predictions to determine consensus in classification tasks.
However, human cognition extends beyond sequential reasoning—it includes metacognitive processes that evaluate confidence. A junior employee demonstrates maturity by recognizing knowledge gaps and seeking help when uncertain. As humans acquire context through research or consultation, their reasoning refines and confidence in providing solutions increases. The capacity to accurately articulate confidence levels in natural language is a key indicator of competence and trustworthiness — a capability largely unexplored in LLMs.
Related Work
Recent work from Anthropic, IBM Research AI, and Meta FAIR has explored LLM self-evaluation, metacognition (overthinking and underthinking), and self-reflection frameworks, establishing the importance of model introspection and confidence calibration.
OptimalThinkingBench [1] measures when LLMs “think” too much on easy questions and too little on hard ones, pairing OverthinkingBench (1,440 simple queries) with UnderthinkingBench (11 reasoning tasks). Evaluating 33 models revealed that no system balances accuracy and efficiency—“thinking” models often waste hundreds of CoT tokens without gains on trivial queries. While the industry has begun focusing on what it means to “think,” this work doesn’t explore natural language confidence scores or their value in evaluating self-awareness. Our blog extends this by optimizing “overthinking” to yield higher prediction accuracy.
SELF-RAG [2] trains models to monitor their reasoning via special “reflection tokens” (retrieve/no-retrieve, relevance, support), making retrieval on-demand and behavior controllable at inference. The model selectively allocates effort and checks claim support before proceeding, tying thinking to metacognition. We apply this concept by monitoring LLM reasoning through natural language confidence scores and providing additional context when confidence is low.
As conversational interfaces and agent-to-agent communication grow, knowing when to add additional information becomes crucial for building trust and enabling agents to exchange context like humans do.
Problem Formulation
Reasoning-capable models (GPT-4o, GPT-5, o3, Gemini 2.5, Claude) provide visibility into step-by-step problem decomposition. Consider the query “Which continent is the US in?” with confidence-augmented reasoning:
- Thought 1: What are the total number of continents? → 7 continents. Confidence: 90%
- Thought 2: What are the countries per continent? → [Lists countries]. Confidence: 40%
- Thought 3: Is the US part of any continent? → Yes, South America. Confidence: 90%
This produces an incorrect conclusion. Without confidence scores, diagnosing where reasoning failed is difficult. However, if the model recognized its knowledge gap at Thought 2 (40% confidence), a system could automatically provide context via tool calls—such as querying a geographical database—before proceeding [3].
Accurate confidence calibration directly impacts trust. Just as senior employees trust junior colleagues who articulate knowledge boundaries, users trust LLMs that signal uncertainty reliably. This yields an interesting idea, organizations developing LLMs, to augment simple white-collar jobs, with accurate confidence assessment will establish trust faster.
This study evaluates how confidence self-awareness has evolved across 2 OpenAI model generations. We introduce thought engineering—the systematic approach to managing and measuring confidence self-awareness in LLMs—and present automated confidence refinement, determining optimal confidence thresholds for triggering additional context retrieval, or resorting to a default classification outcome when the natural language confidence score is too low.
Experiment
Dataset
Hugging Face link: https://huggingface.co/datasets/allenai/scifact
We evaluate our framework on SciFact, a scientific claim verification benchmark. The dataset pairs scientific claims with research paper abstracts, requiring classification as:
- SUPPORT: Evidence confirms the claim
- CONTRADICT: Evidence refutes the claim
- NOINFO: No relevant information found
We sampled 200 claims to test across multiple models. Each requires retrieving relevant papers from 5,000+ scientific abstracts and classifying the claim-evidence relationship. This two-stage task (retrieval + classification) mirrors real-world scenarios where LLMs must identify relevant context before reasoning.
For our use case, our golden examples only contained of claims that are NOINFO. This is because we want to evaluate if the LLM can be confident in situations that it does not have enough context, or could not find enough relevant information to increase its confidence from its pre-trained dataset to create a conclusion.
The Critical Importance of NOINFO Classification
NOINFO F1 score emerges as the most critical metric for evaluating confidence-aware reasoning. It directly measures whether models can recognize insufficient context and are aware of the situation. Our threshold optimization framework converts low-confidence SUPPORT/CONTRADICT predictions to NOINFO, meaning NOINFO F1 captures both: (1) the model’s ability to recognize genuinely insufficient evidence, and (2) confidence-based filtering preventing overconfident misclassifications.
Evaluation Methodology
Retrieval and Search Process
Unlike traditional classification where context is provided, our experiment requires LLMs to actively query the corpus. This tests whether models can:
- Formulate effective search queries from claims
- Assess if retrieved evidence is sufficient based on confidence
- Recognize when additional retrieval is needed
We implement a simple term-overlap retrieval system (matching 4+ character words, with 2x weight for title matches). While basic, this ensures all strategies use the same retrieval backend, isolating confidence-aware reasoning’s effect on query reformulation. The LLM only reformats queries and adds retrieval when aware of low confidence.
Three Retrieval Strategies
We compare three retrieval strategies to test how confidence-aware reasoning affects performance:
1. Naive: Direct Query Generation
The model generates search queries without confidence assessment:
Generate 2-3 scientific search queries to find research papers that could verify or refute this claim.
Claim: \{claim\}
Focus on:
- Key entities (genes, proteins, drugs, diseases)
- Core mechanisms or relationships mentioned
- Specific phenomena or effects
Return JSON: \{"search_queries": ["query1", "query2", "query3"]\}
After retrieving papers, classification proceeds:
Verify this scientific claim using the provided evidence.
Claim: \{claim\}
Evidence from papers:
\{retrieved_papers\}
Classify as:
- SUPPORT: The papers provide evidence that confirms the claim
- CONTRADICT: The papers provide evidence that refutes the claim
- NOINFO: The papers don't contain relevant information about this specific claim
Return JSON: \{"label": "SUPPORT"|"CONTRADICT"|"NOINFO", "confidence": 0.0-1.0, "justification": "explanation"\}
2. Overthinking: Pre-Reasoning Before Retrieval
The model analyzes the claim before searching, adapting strategy based on initial confidence:
You're a scientific claim verifier. Before searching, analyze this claim.
Claim: \{claim\}
Think step-by-step:
1. What is this claim asserting? What are the key concepts?
2. What evidence would SUPPORT this? What would CONTRADICT it?
3. Initial confidence in finding relevant evidence (0.0-1.0)
4. Search strategy:
- If confidence < 0.5: Generate 3-4 broad exploratory queries
- If confidence 0.5-0.8: Generate 2-3 targeted queries
- If confidence > 0.8: Generate 1-2 precise queries
Return JSON: \{"reasoning": "your analysis", "initial_confidence": 0.0-1.0, "search_queries": [...]\}
This tests whether pre-reasoning about confidence improves retrieval quality.
3. Automated Confidence Refinement (Our Framework)
Our proposed framework retrieves papers first, then assesses if evidence is sufficient:
Step 1: Initial Retrieval (same as naive)
Step 2: Confidence Assessment
You retrieved these papers for the claim. Assess if they provide sufficient evidence.
Claim: \{claim\}
Retrieved Papers:
\{paper_previews\}
Evaluate:
1. Confidence these papers can verify/refute the claim (0.0 = need more, 1.0 = sufficient)
2. What critical information is MISSING to properly assess the claim?
3. Should additional papers be retrieved? (yes only if confidence < 0.7)
Return JSON: \{"confidence": 0.0-1.0, "need_refinement": "yes"|"no", "gaps": "what's missing"\}
Step 3: Conditional Refinement
If confidence is below the model-specific threshold AND refinement is needed:
Initial retrieval was insufficient. Missing information: \{identified_gaps\}
Claim: \{claim\}
Generate 1-2 NEW refined search queries to fill these specific gaps.
Focus on what's missing, not what you already retrieved.
Return JSON: \{"refined_queries": ["query1", "query2"]\}
Key insight: This framework tests whether LLMs can accurately self-assess confidence and know when to seek additional context—analogous to knowing when to ask for help.
Evaluation Metrics
We use NOINFO F1 score as the primary metric because it measures the model’s ability to recognize insufficient evidence. Since our golden dataset contains only NOINFO examples, NOINFO F1 captures both precision (correctly identifying lack of information) and recall (not overconfidently misclassifying as SUPPORT/CONTRADICT). This directly evaluates self-awareness: can the model recognize when it doesn’t know?
The experiment uses 200 parallel workers for efficient processing across 1,000 total predictions (200 claims × 5 models).
Automated Confidence Refinement
We test 2 models: o3, and gpt-5. Initially, 50 claims determined ideal confidence thresholds per model. We then scaled to 200 claims for final testing.
Each prediction includes a confidence score, enabling two threshold-based optimizations:
- Classification Threshold: Converts low-confidence NOINFO predictions to NOINFO.
- Iterative Refinement Threshold: Triggers additional retrieval when confidence is insufficient.
To calculate these confidence thresholds, we used the grid search algorithm [5].
Grid Search Optimization: We perform exhaustive grid search over threshold combinations to find optimal values per model. For each combination, we apply thresholds to raw outputs, compute NOINFO F1 score, and select the configuration maximizing F1.
This is impactful because it:
- Removes manual tuning: Automatically discovers optimal operating points per model
- Accounts for model differences: Models have different confidence calibration (o3 may be overconfident, gpt-5 well-calibrated)
- Maximizes real-world utility: Finds the balance between conservative (excessive NOINFO) and aggressive (wrong classifications)
Mathematical Formulation:
$$T_\tau(\hat{y}_i, c_i) = \begin{cases} \text{NOINFO} & \text{if } c_i < \tau \land \hat{y}_i \neq \text{NOINFO} \\ \hat{y}_i & \text{otherwise} \end{cases}$$$$\tau^* = \arg\max_{\tau \in \Theta} F1_{\text{NOINFO}}(\tau)$$Where:
- \(T_\tau(\hat{y}_i, c_i)\) - transformation function with threshold \(\tau\)
- \(c_i\) - confidence score for instance \(i\)
- \(\tau\) - threshold parameter
- \(\hat{y}_i\) - predicted label for instance \(i\)
- \(\tau^*\) - optimal threshold
- \(\land\) - logical AND operator
- \(F1_{\text{NOINFO}}(\tau)\) - F1 score as a function of threshold
This automated approach is critical because models have fundamentally different confidence calibration. Grid search identifies each model’s “sweet spot” between conservative (excessive NOINFO) and aggressive (incorrect SUPPORT/CONTRADICT).
Results
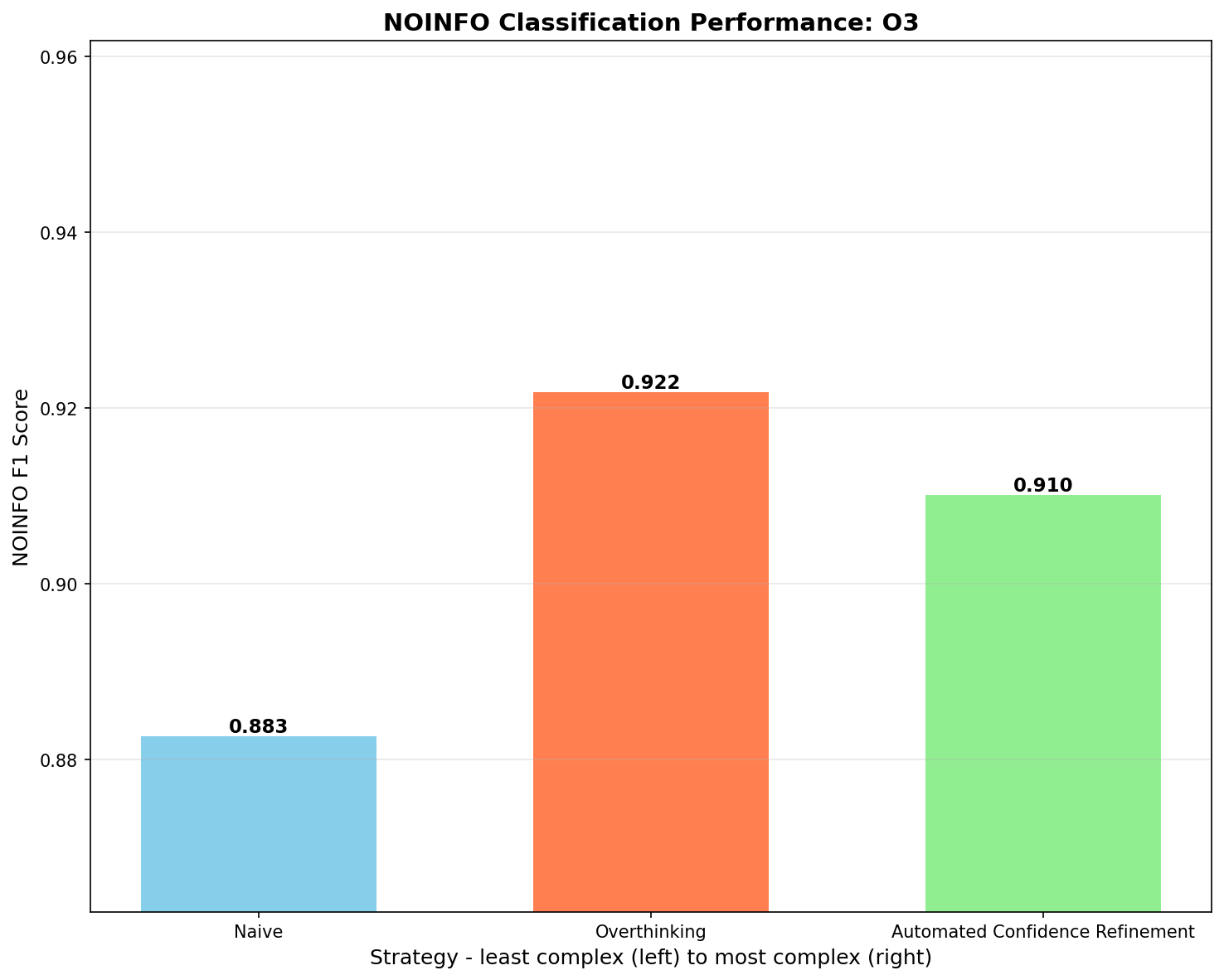
Performance (NOINFO F1 scores) for the o3 model
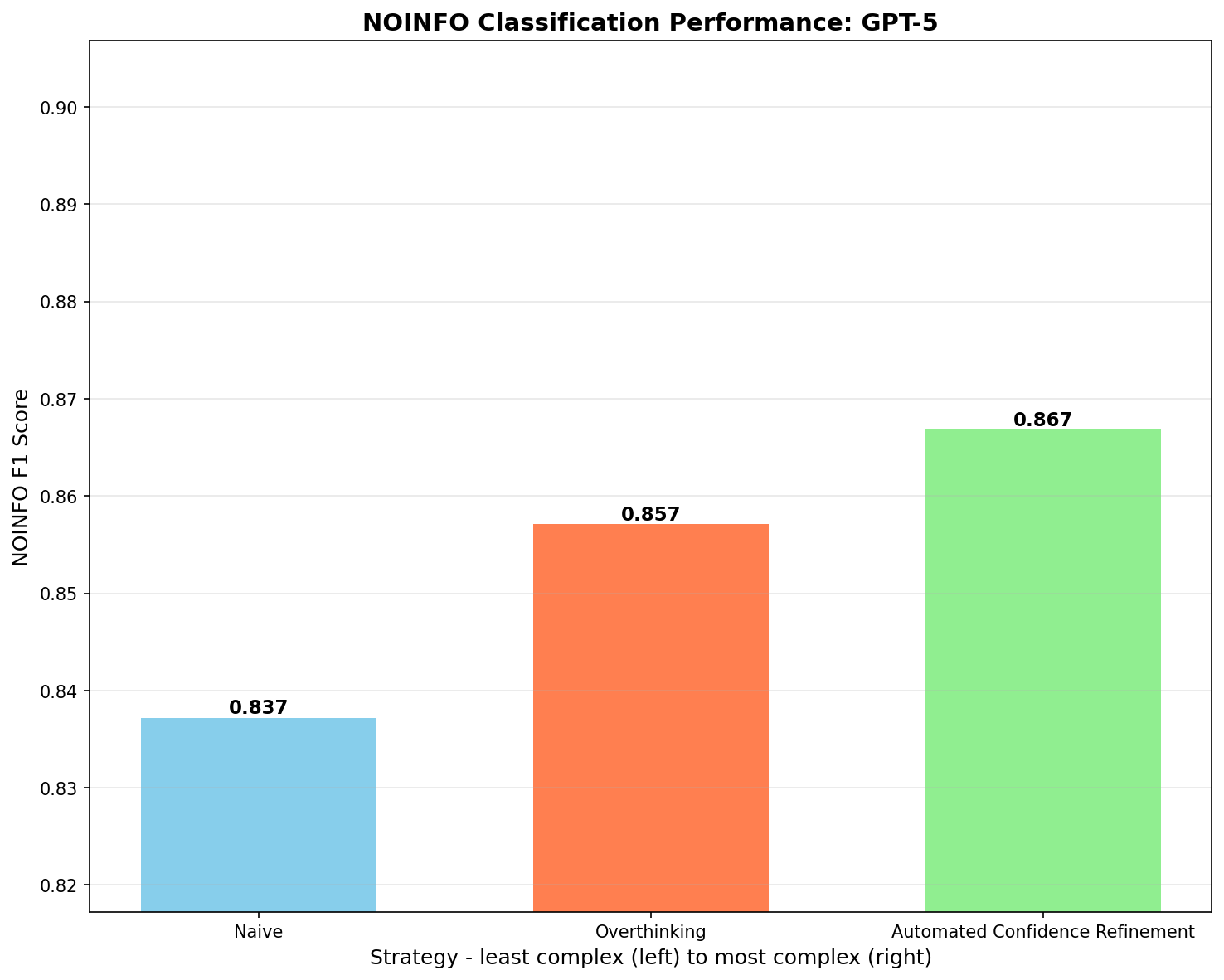
Performance (NOINFO F1 scores) for the gpt-5 model
F1 score trends reveal similar patterns across model generations:
- Older model (o3): We can see that thought engineering thinking techniques outperform naive techniques
0.883 (Naive) < 0.910 (Iterative Refinement - almost statistically significant) < 0.922 (Overthinking - statistically significant)
- Newer model (gpt-5): We can see that thought engineering thinking techniques outperform naive techniques.
0.837 (Naive) < 0.857 (Overthinking) < 0.867 (Iterative Refinement - statistically significant)
We also performed permutation statistical significance tests on the 200 samples above. Below describes how we calculated this, and the results.
Understanding Permutation Significance Tests
What Are Permutation Tests?
Permutation tests are non-parametric statistical methods that assess whether observed differences between two classifiers are statistically significant without making distributional assumptions. They work by repeatedly shuffling predictions between the two classifiers to generate a null distribution of differences that would occur purely by chance. This makes them particularly valuable for small sample sizes (like our n=200) where parametric test assumptions may not hold, and allows us to test the null hypothesis that two classifiers are equivalent in performance.
The p-value represents the probability of observing a difference as extreme as the actual difference if the classifiers were truly equivalent, computed by comparing the observed accuracy difference against 10,000 random permutations. A p-value less than 0.05 indicates statistical significance, meaning the observed difference would occur by chance less than 5% of the time. We report confidence as 1 - p-value, where higher values indicate stronger evidence of a real performance difference between classifiers.
Mathematical Formulation
Given two classifiers \(C_1\) and \(C_2\) evaluated on \(n\) test instances:
1. Observed difference:
\[ \delta_{obs} = \text{acc}(C_1) - \text{acc}(C_2) \]
where
\[ \text{acc}(C) = \frac{1}{n} \sum_{i=1}^{n} \mathbb{I}(\text{pred}_i = \text{gold}_i) \]
2. Null hypothesis: \(H_0: \delta = 0\) (classifiers are equivalent)
3. Permutation procedure:
For each permutation \(k = 1, \ldots, K\) (where \(K = 10{,}000\)):
- For each instance \(i\): With probability 0.5, swap \((\text{pred}_{1,i}, \text{pred}_{2,i})\)
- Compute permuted difference: \(\delta_k = \text{acc}_k(C_1) - \text{acc}_k(C_2)\)
4. P-value computation:
\[ p = \frac{1}{K} \sum_{k=1}^{K} \mathbb{I}(|\delta_k| \geq |\delta_{obs}|) \]
where \(\mathbb{I}(\cdot)\) is the indicator function that equals 1 when the condition is true and 0 otherwise.
5. Decision rule: Reject \(H_0\) if \(p < \alpha\) (typically \(\alpha = 0.05\))
Statistical Significance Results Summary
| Model | Comparison | Sample Size | Confidence | p-value | Significant? |
|---|---|---|---|---|---|
| o3 | Overthinking vs Automated Refinement | 200 | 81.8% | 0.1824 | No |
| o3 | Automated Refinement vs Naive | 200 | 93.4% | 0.0659 | No |
| o3 | Overthinking vs Naive | 200 | 99.0% | 0.0101 | ✓ Yes |
| gpt-5 | Overthinking vs Automated Refinement | 200 | 61.9% | 0.3815 | No |
| gpt-5 | Automated Refinement vs Naive | 200 | 95.2% | 0.0480 | ✓ Yes |
| gpt-5 | Overthinking vs Naive | 200 | 86.1% | 0.1385 | No |
Key Findings:
- For o3: Overthinking shows a statistically significant improvement over Naive (p = 0.0101)
- For o3: Almost achieved statistical significance that iterative refinement performs better than naive methods (p = 0.0659)
- For gpt-5: Automated Refinement shows a statistically significant improvement over Naive (p = 0.0480)
- Most other comparisons do not reach statistical significance at the α = 0.05 threshold
Note: Confidence = 1 - p-value. Bold entries indicate statistically significant results (p < 0.05).
Conclusion
Our results demonstrate a clear trend: pure thinking models (o3) and mixed routers LLMs (gpt-5), perform better in self-awareness evaluation confidence assessments. Mixed router models (gpt-5) seem to benefit more with iterative refinement (3.6% and statistically significant), than pure thinking models (o3) where overthinking has a stronger effect (4.4% and statistically significant).
This validates our hypothesis: modern thinking LLMs can be engineered to recognize insufficient reasoning and proactively seek additional context. Thought engineering enables models to operate like professionals who know when to request more information. As models improve, this metacognitive ability should become more reliable, transforming confidence scores into more significant actionable signals for optimizing multi-classification, through threshold tuning and conditional retrieval.
This confidence iterative refinement framework offers a principled alternative: let models reason naturally, then assess confidence post-prediction to determine if additional context is needed. As LLMs advance, this pattern should strengthen — future models should exhibit better confidence calibration, making automated refinement a reliable strategy for high-stakes reasoning tasks requiring accuracy and self-awareness.
Assumptions and Caveats
This framework assumes developers have access to additional APIs/tools for adding context when the LLM has low confidence.
We used a sample size of 200 claims. Running 1,000 total requests (2 models × 1000 claims) plus grid search optimization is costly—hundreds of dollars. While 1,000+ claims would be ideal, 200 provides meaningful insights.
The key finding is not absolute performance differences between models (e.g., o3 vs. gpt-5), but rather within-model trends for thought-engineering: older models (o3) and newer models (gpt-5) perform better with thought engineering methods (overthinking, confidence-based refinement) regardless of their architecture type.
Future application
~3%-5% boosts in F1 scores, though statistically significant, may not have a massive impact on users trusting LLMs more.
This research does not propose that thought engineering can be the solution to gain “trust” with LLMs. Instead, it claims and proves that thinking models are indeed “aware,” and that we can use thought engineering to add more context and improve accuracy scores for multiclassification problems.
Research labs could build future LLMs to produce more accurate confidence scores in their responses to help developers/users know when to add more context, given that these LLMs are inherently “aware”.
References
[1] - OptimalThinkingBench: Evaluating Over and Underthinking in LLMs; FAIR at Meta, Carnegie Mellon (https://arxiv.org/pdf/2508.13141v1)
[2] - SELF-RAG: LEARNING TO RETRIEVE, GENERATE, AND CRITIQUE THROUGH SELF-REFLECTION; University of Washington, Allen Institute for AI, IBM Research AI (https://arxiv.org/pdf/2310.11511)
[3] - Prompt Engineering; Weng, Lilian, (https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/)
[4] - Tool Use; Weng Lilian, (https://lilianweng.github.io/posts/2023-06-23-agent/#component-three-tool-use)
[5] Grid Search, Random Search, Genetic Algorithm: A Big Comparison for NAS; Department of Computer Engineering Ternopil National Economic University, (https://arxiv.org/pdf/1912.06059)