Research code: https://github.com/pranavc28/temperature-ocr-vqa
Definitions
Temperature in LLMs controls how predictable or exploratory a model’s outputs are. Low temperature = consistent and factual, good for precise tasks. High temperature = more diverse, good for creative tasks—but also riskier.
Visual Question Answering (VQA) is about answering questions directly from images. For OCR tasks, like reading a book cover, VQA can outperform raw OCR because it focuses only on what’s asked (e.g., “Who’s the author?”) instead of dumping every piece of text.
Background
Temperature tuning is often used to improve generative tasks like writing or summarization. But most of that research is text-only. I wanted to see if the same effect shows up in multimodal tasks, specifically VQA for OCR-heavy images. The hypothesis: maybe more “randomness” helps with broad or open-ended questions, especially “What” vs. “Is” types.
Experiment
Using the OCR-VQA dataset, I tested 1,000 book cover questions across a range of temperatures. Accuracy was measured against gold answers. Questions were clustered into groups (most open ended questions, medium open ended questions, least open ended questions, and wh-questions), and I plotted accuracy vs. temperature for each cluster.
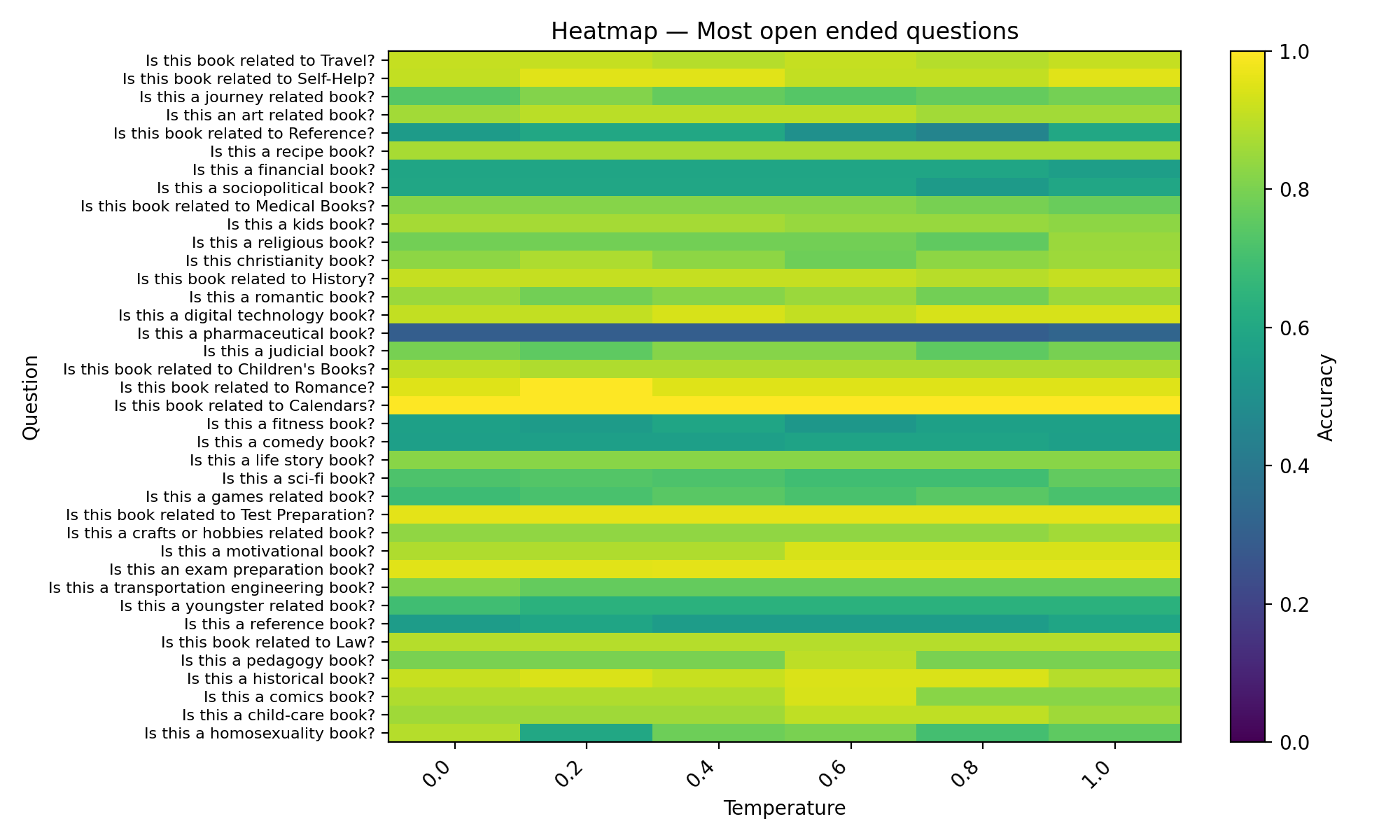
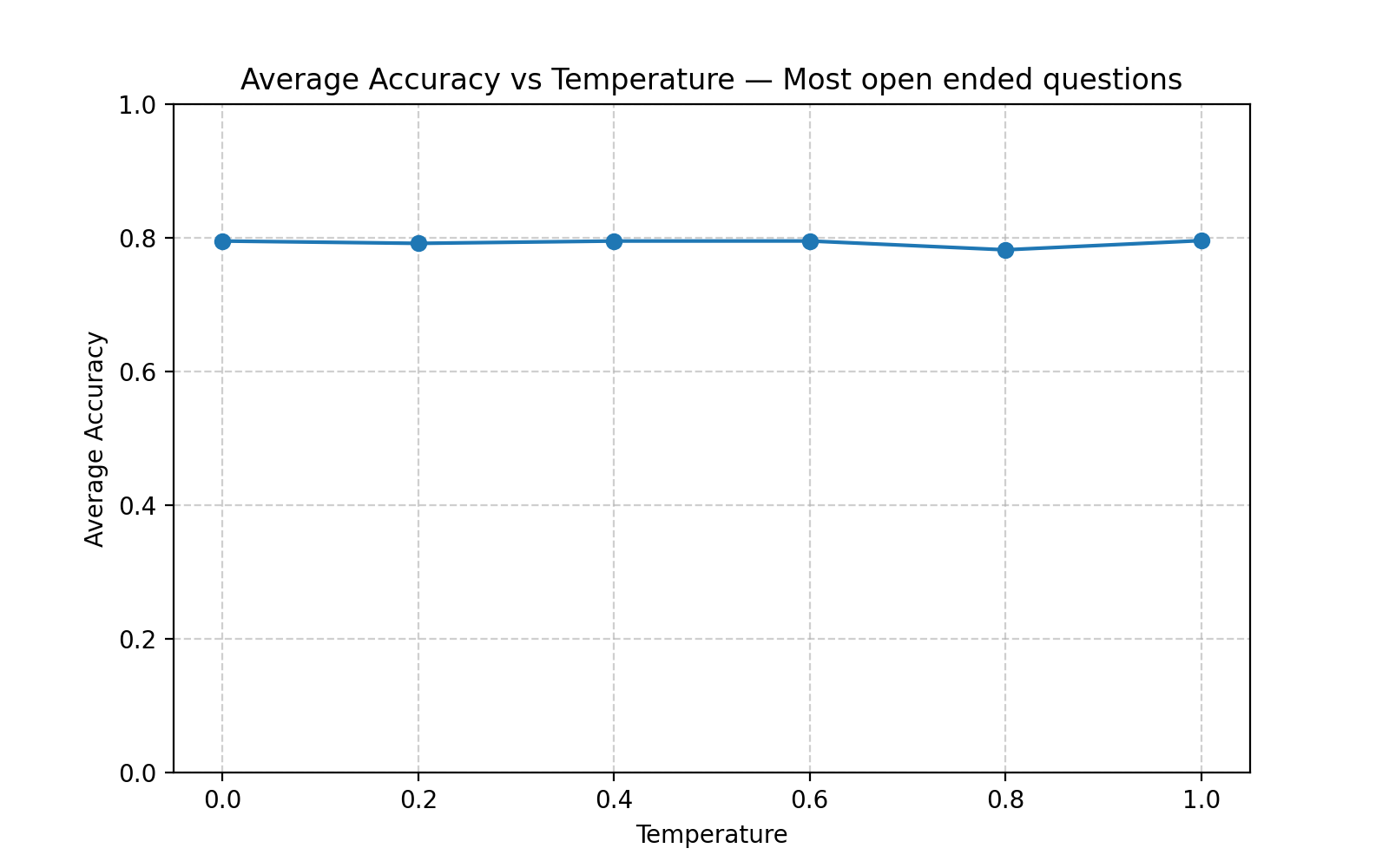
Most open ended questions (1 option) - Asked the LLM to give a binary answer based on one requirement. Such as, is this book a romance novel?
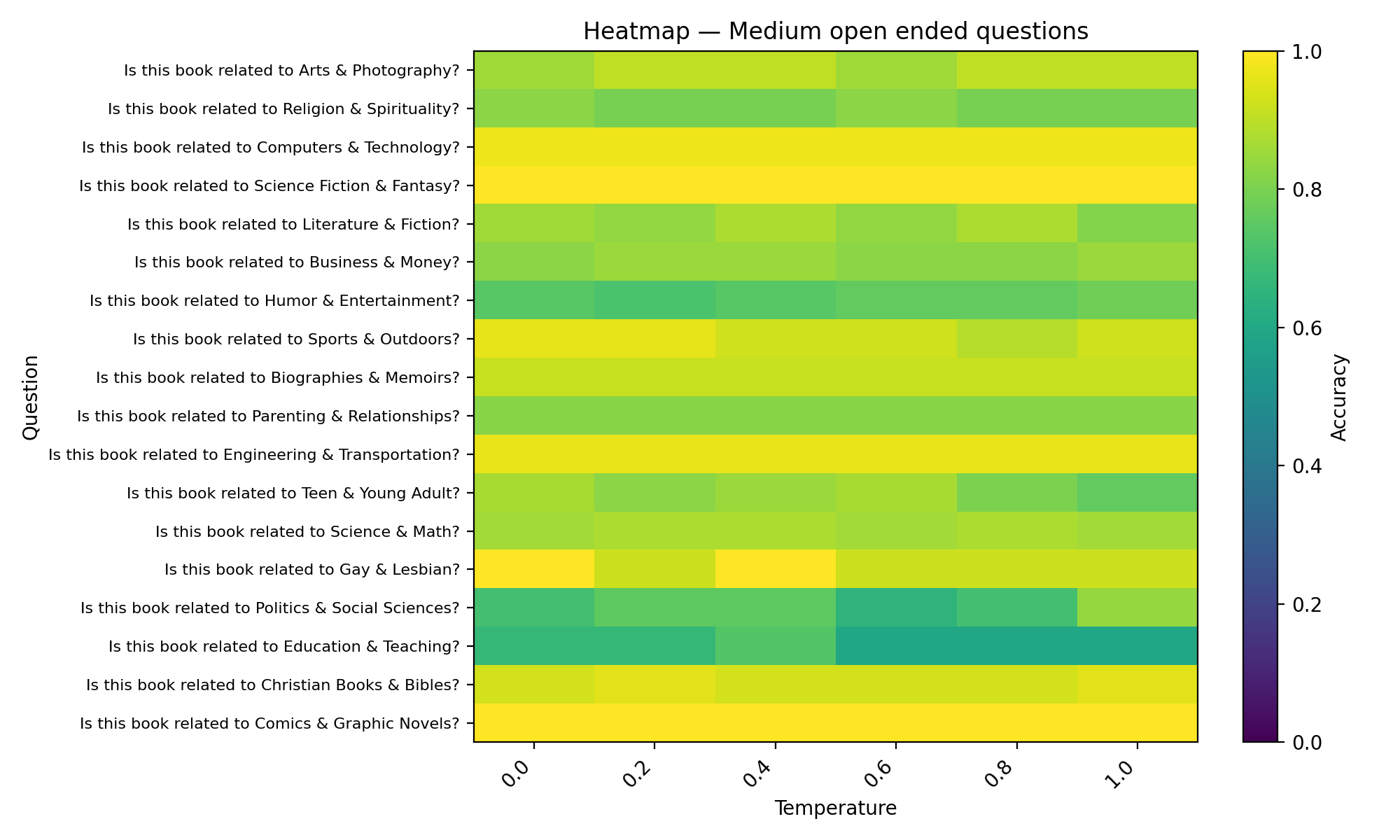
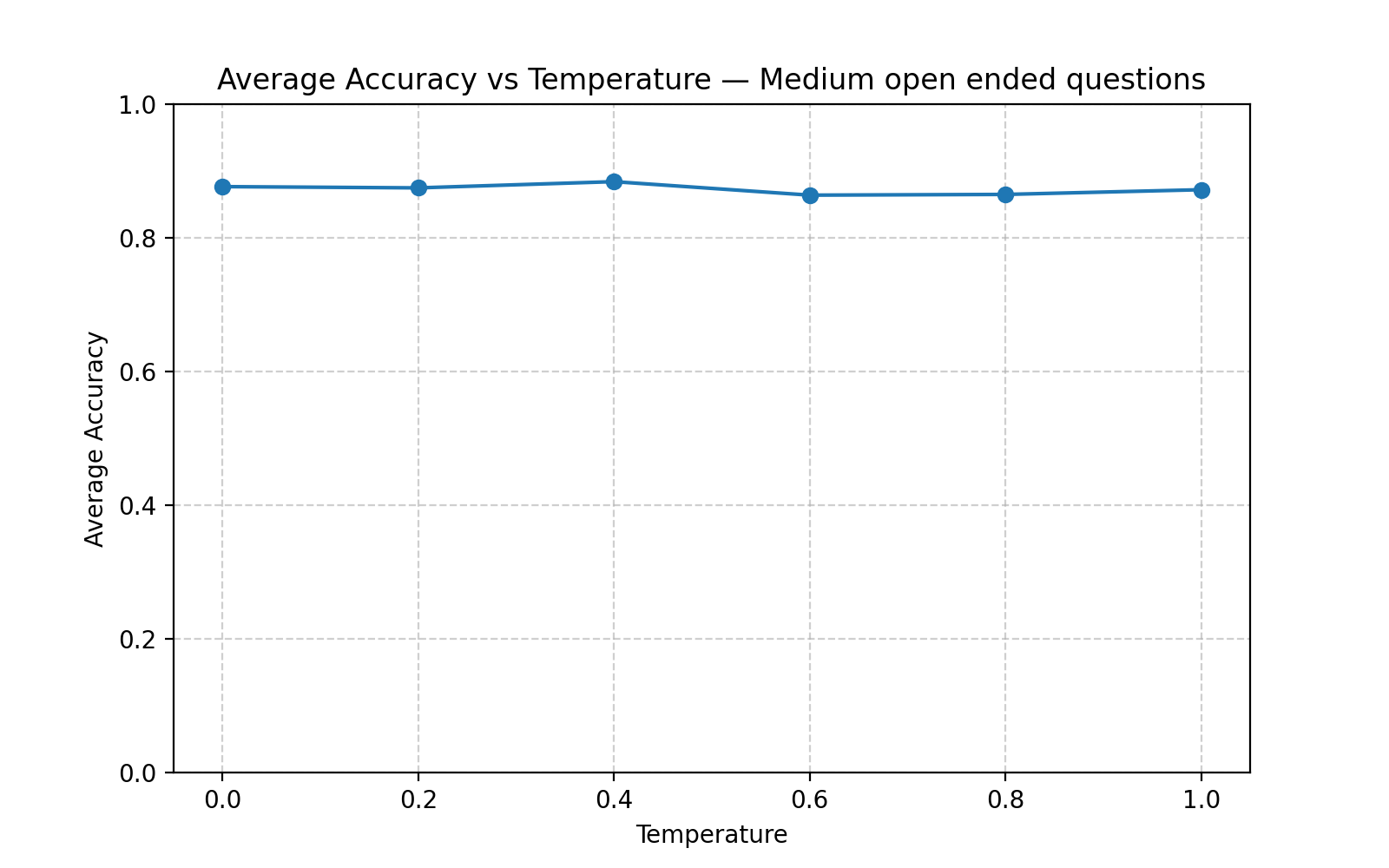
Medium open ended questions (2 options) - Asked the LLM to give a binary answer based on 2 options. Such as, is this book a teen romance & adult romance novel?
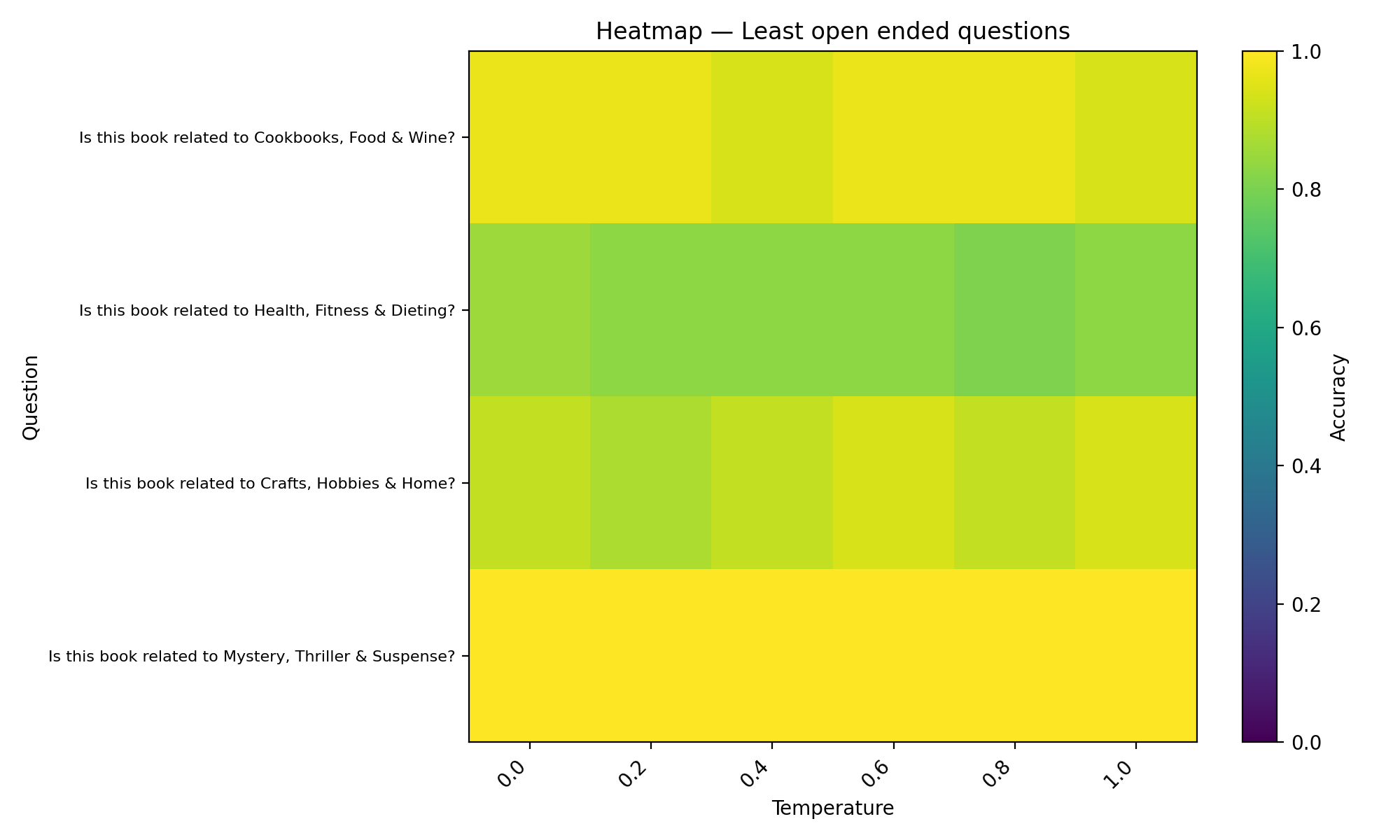
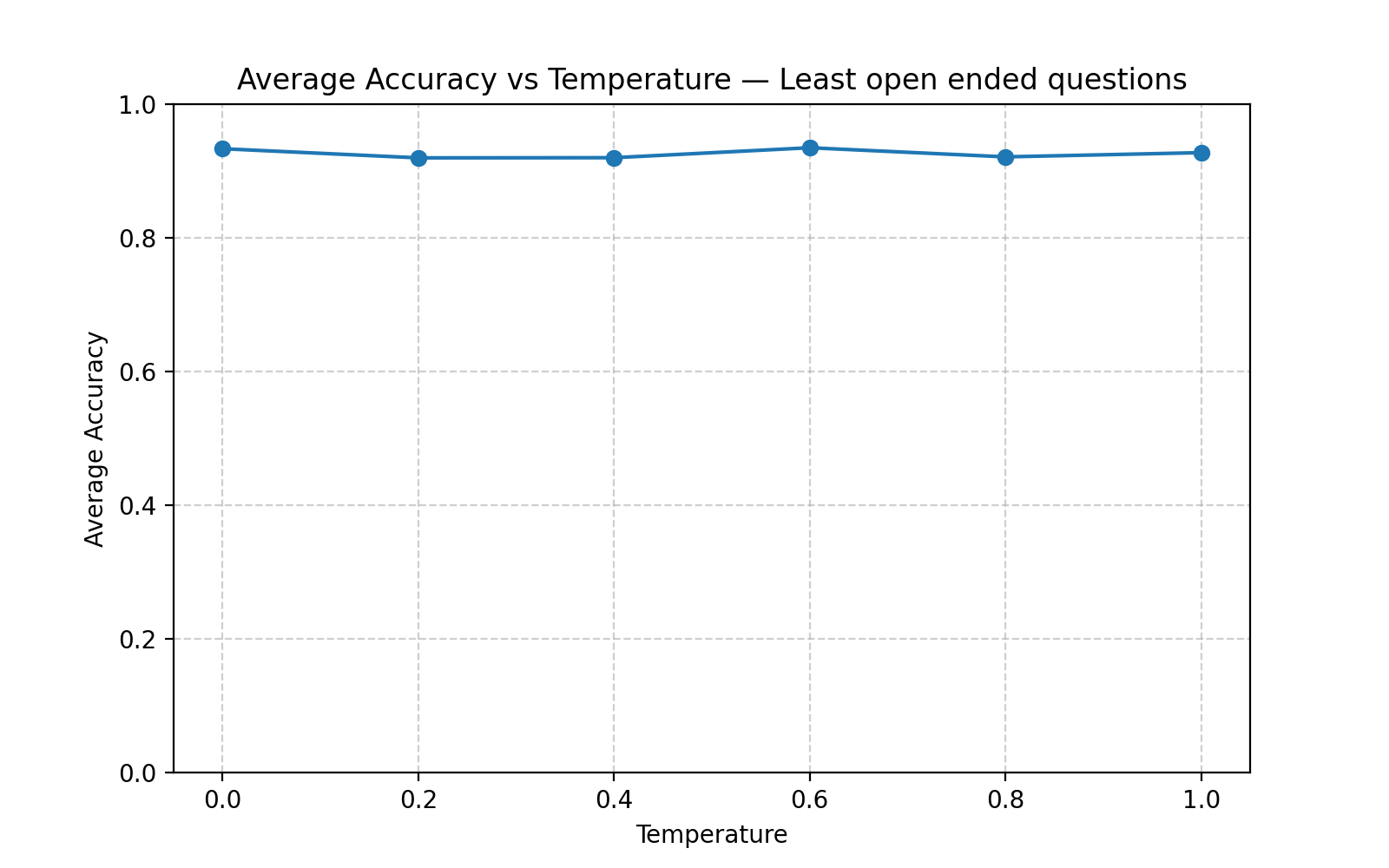
Least open ended questions (3 options) - Asked the LLM to give a binary answer based on 3 options. Such as, is this book a teen romance, adult romance, & high school romance novel?
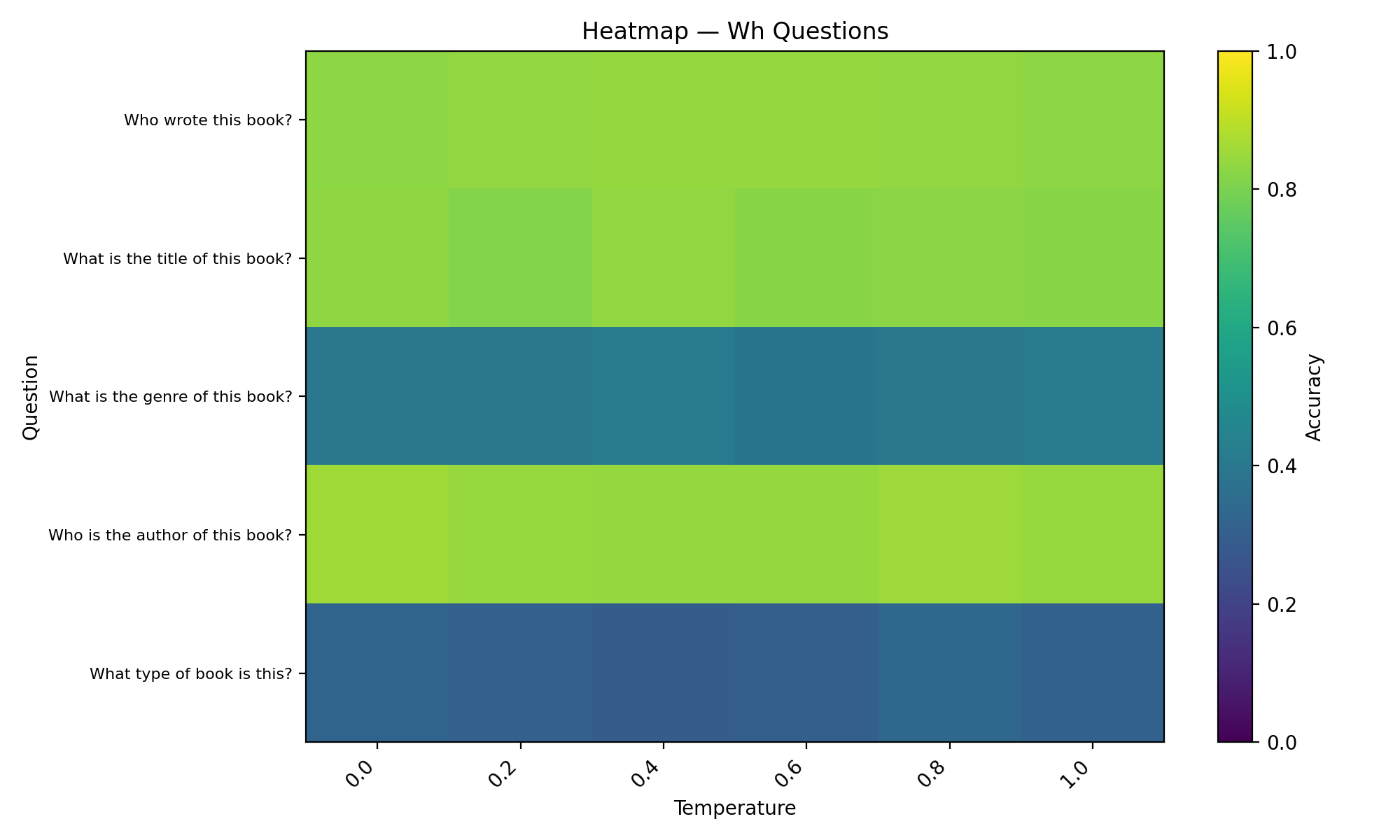
Wh question- Questions that start with “Wh”, such as What edition is this book?
I used an LLM judge to score a 1 or a 0 if the predicted answer was close to the golden answer with a high accuracy being 1.
Results
The outcome was clear: temperature had little to no effect. Accuracy curves across all question types stayed nearly flat. Whether the model was asked “Is this a romance?” or “What edition is this?”, increasing randomness didn’t improve results.
Most open-ended questions accuracy vs temperature plot
Medium open-ended questions accuracy vs temperature plot
Least open-ended questions accuracy vs temperature plot
“Wh” open-ended questions accuracy vs temperature plot
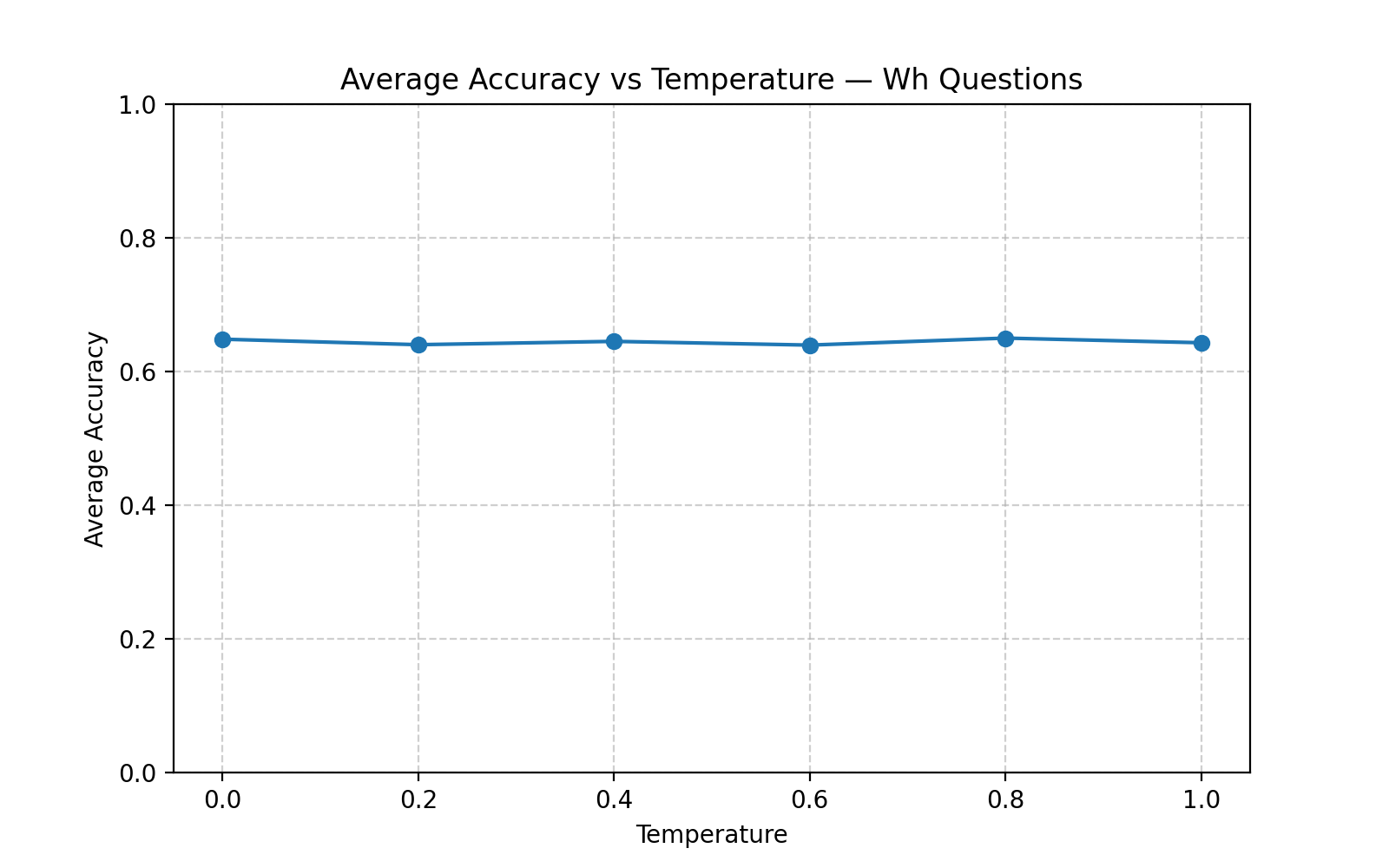
So, why did this happen? OCR-based VQA is about precision. The correct answer is often a single string, like an author’s name or edition number. In such cases, more sampling doesn’t add useful variation—it just risks introducing errors. The bottleneck seems to lie in the OCR pipeline itself; if characters are misread, temperature won’t fix that.
Takeaway: For OCR-focused VQA, temperature tuning isn’t the right lever. Gains will likely come from better OCR integration, data augmentation, or fine-tuning—not from adjusting sampling randomness.
Appendix - heatmaps