“In all things the middle state is to be praised.” - Aristotle
Research code: https://github.com/pranavc28/self-awareness-grpo
LLM: openai/gpt-oss-20b
Datasets: https://github.com/tdiggelm/climate-fever-dataset, https://fever.ai/download/fever/train.jsonl, https://github.com/TalSchuster/VitaminC
Claim
Diverse training datasets improve generalization, with harder examples requiring stronger representation than easier ones to effectively shift model behavior. However, training exclusively on difficult examples fails to transfer to simpler domains—a mixture of both easy and hard examples is necessary for robust cross-domain performance.
The domain considered is self-awareness. Follow my previous blogs for motivation and background.
Motivation
Generealization is starting to become a more spoken buzzword in ML and AI podcasts. I wanted to give it a stab, and try to formulate my own theories especially in the area of self-awareness.
Literature Review
I situate this work within the study of self-awareness in LLMs—the capacity to recognize knowledge boundaries and calibrate outputs accordingly. Prior research shows LLMs are frequently overconfident rather than acknowledging uncertainty [1], while the VitaminC benchmark demonstrated that contrastive evidence training improves calibration by forcing attention to subtle factual distinctions [2]. I extend this by framing self-awareness as trainable: through GRPO, I incentivize correct “Not Enough Info” predictions when evidence is genuinely insufficient, directly addressing the “NA collapse” phenomenon where models exploit the neutral class to avoid penalty.
My claim that diverse training distributions are essential for self-aware generalization builds on hard example mining literature while identifying a critical limitation: training exclusively on difficult datasets fails to transfer to simpler domains. Research confirms hard examples shift model behavior toward nuanced reasoning [3], yet over-specialization degrades foundational performance [4]. I employ GRPO—computing advantages relative to sampled outputs without a separate critic [5]—to reward calibrated predictions across the full difficulty spectrum, ensuring the model develops genuine self-awareness rather than domain-specific shortcuts.
Methodology
I framed this research problem as a fact verification task for self-awareness for each trained model: classifying claims as SUPPORTED (PASS), REFUTED (FAIL), or NOT ENOUGH INFO (NA) given evidence. I constructed mixed training datasets from three benchmarks in different dostributions — FEVER, VitaminC, and ClimateFEVER — to ensure cross-domain generalization.
The training set in total was balanced with approximately 460 NA, 460 PASS, and 380 FAIL examples. I used different random seeds for training (42) and evaluation (43) to ensure strict train-test separation. Each claim was paired with retrieved evidence text from Wikipedia or the respective dataset source.
To investigate the role of dataset composition in model generalization, I conducted training runs across three distinct configurations:
Hard-only configuration: Training exclusively on ClimateFEVER and VitaminC—the two datasets where the base model exhibits weaker performance—excluding the easier FEVER dataset entirely.
Hard-weighted configuration: Training on all three datasets but with distributions favoring the harder ClimateFEVER and VitaminC examples, while including a smaller proportion of FEVER examples.
Balanced configuration: Training with equal representation from all three datasets, giving each source comparable weight in the training mixture. This experimental design enabled direct comparison of how training data diversity and difficulty distribution affect downstream performance across both challenging and straightforward fact verification domains.
I implemented Group Relative Policy Optimization (GRPO) with LoRA fine-tuning (rank 32) on a GPT-OSS-20B base model. The reward function combined four components: class-weighted accuracy rewards favoring PASS/FAIL predictions, a false-NA penalty, an exploration bonus to prevent NA collapse, and a format compliance penalty given that the model is pretrained and has not undergone supervised fine tuning for instruction following. Training ran for 200 steps with batch size 32, group size 8, and learning rate 5e-6 with AdamW optimization. I set sampling temperature to 0.3 to balance exploration with training stability, given that over this temperatre the formatting penalty would take longer to converge to 0.
For the experimental comparison, I evaluated two checkpoints: a format-only baseline (learned output structure but not accuracy) and the full GRPO model with accuracy optimization. Both models received identical prompts and classified the same 1,000 evaluation examples per dataset (500 NA, 250 PASS, 250 FAIL). I used the exact same prompt template during evaluation as during training to ensure fair comparison. This paired design allows direct comparison of predictions on identical test instances.
I assessed statistical significance using paired bootstrap testing (10,000 iterations) across accuracy, macro F1, and per-class F1 scores with a threshold of p < 0.01. I computed 95% confidence intervals for all metric differences and employed McNemar’s test to quantify discordant predictions. This approach ensures observed improvements reflect genuine capability differences rather than sampling variance.
Reward Function Deep Dive in GRPO
The total reward for each sampled completion is:
\[ R = R_{\text{correct}} + R_{\text{false\_na}} + R_{\text{explore}} + R_{\text{fmt}} \]Component Definitions:
\[ R_{\text{correct}} = \begin{cases} +4.0 \times w_{\hat{y}} & \text{if } \hat{y} = y \\ -0.5 \times w_{\hat{y}} & \text{if } \hat{y} \neq y \end{cases} \]\[ R_{\text{false\_na}} = \begin{cases} -0.5 \times w_{\text{NA}} & \text{if } \hat{y} = \text{NA} \land y \neq \text{NA} \\ 0 & \text{otherwise} \end{cases} \]\[ R_{\text{explore}} = \begin{cases} +8.0 & \text{if } \hat{y} \in \{\text{PASS}, \text{FAIL}\} \\ 0 & \text{if } \hat{y} = \text{NA} \end{cases} \]\[ R_{\text{fmt}} = \begin{cases} -0.25 & \text{if output format invalid} \\ 0 & \text{otherwise} \end{cases} \]Where:
- \(\hat{y}\) is the predicted label (PASS, FAIL, or NA)
- \(y\) is the ground truth label
- \(w_{\hat{y}}\) is the class weight for the predicted label
Class Weights:
| Class | Weight | Rationale |
|---|---|---|
| \(w_{\text{NA}}\) | 0.15 | Low weight discourages defaulting to “safe” NA |
| \(w_{\text{PASS}}\) | 2.5 | Higher weight—PASS requires confident assertion |
| \(w_{\text{FAIL}}\) | 3.5 | Highest weight—FAIL is hardest to predict correctly |
Component Explanations:
| Component | Purpose |
|---|---|
| \(R_{\text{correct}}\) | Accuracy signal—rewards correct predictions, penalizes incorrect ones |
| \(R_{\text{false\_na}}\) | Penalizes NA predictions when evidence clearly exists |
| \(R_{\text{explore}}\) | Rewards PASS/FAIL attempts to encourage exploration |
| \(R_{\text{fmt}}\) | Penalizes invalid output format |
Design Rationale. The asymmetric class weights (NA=0.15, PASS=2.5, FAIL=3.5) combat NA collapse—the model’s tendency to default to the “safe” NA prediction. The large exploration bonus (+8.0) makes attempting PASS/FAIL predictions immediately rewarding, while the gentle incorrect penalty (0.5) reduces risk aversion during exploration.
Training Curves
Cumulative Rewards (In order of best performing in results to worst)
The cumulative reward curves reveal distinct learning dynamics across the three training configurations.
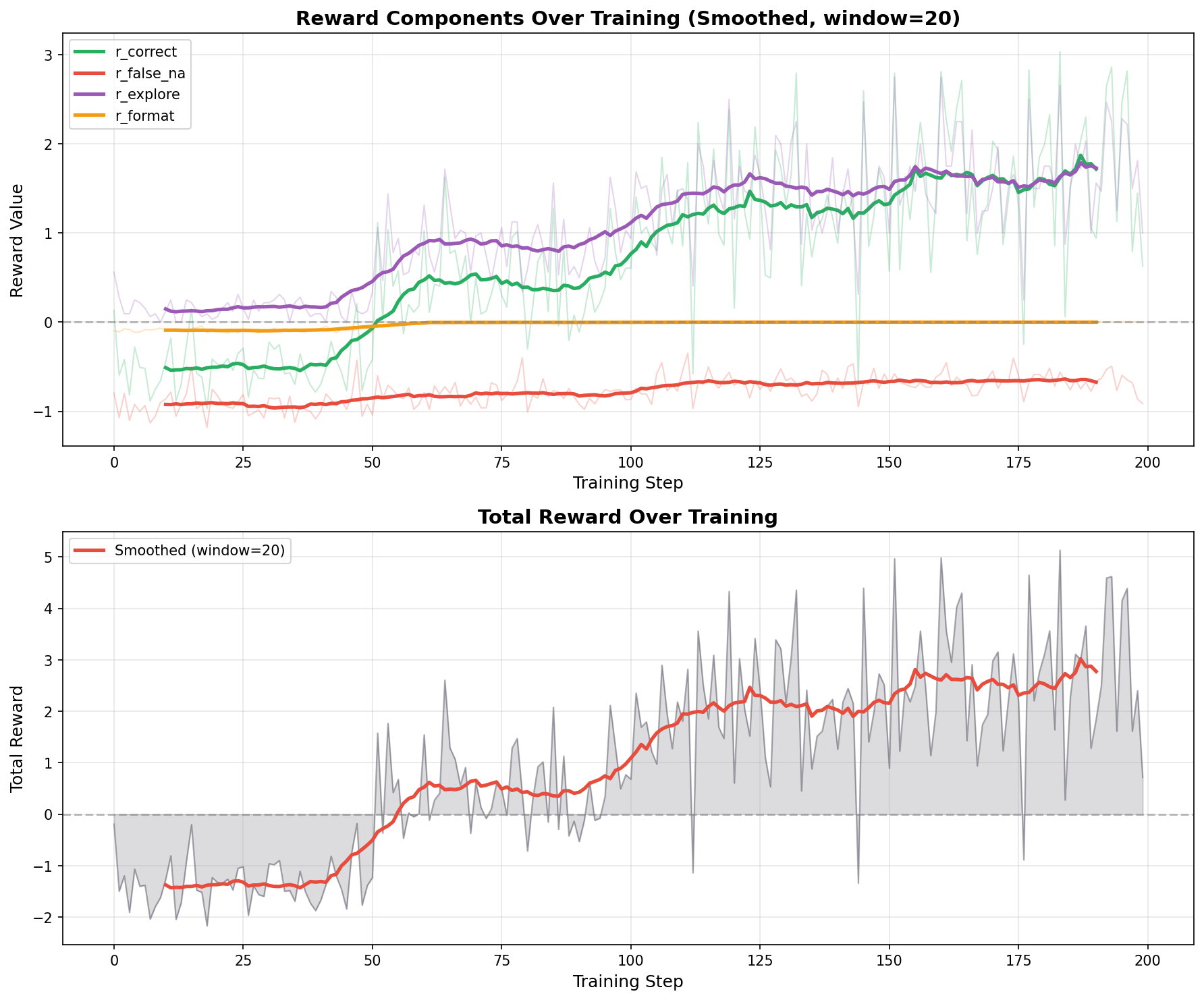
Hard-Weighted, all 3 datasets (Best)
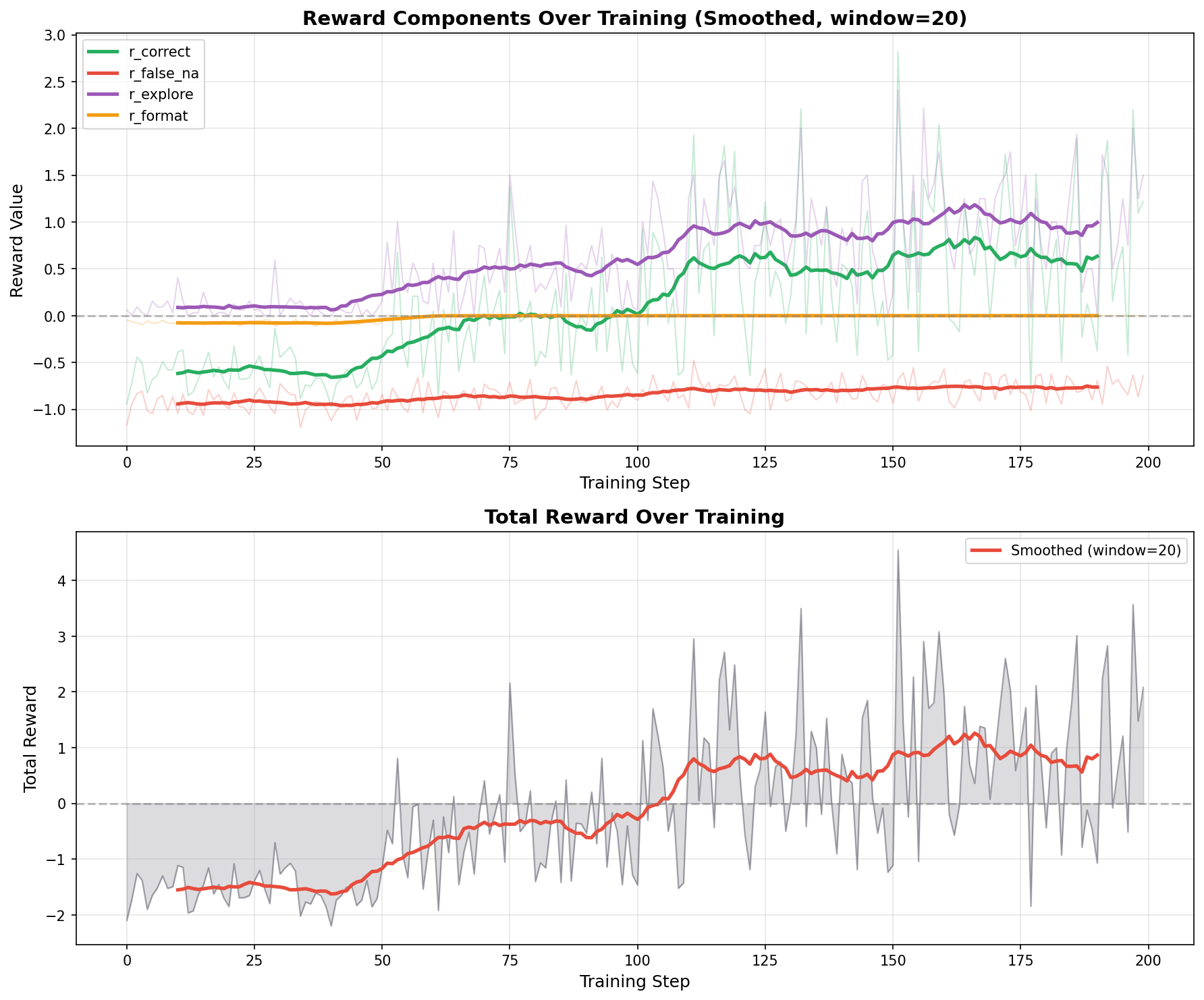
Balanced, all 3 datasets (Worse)
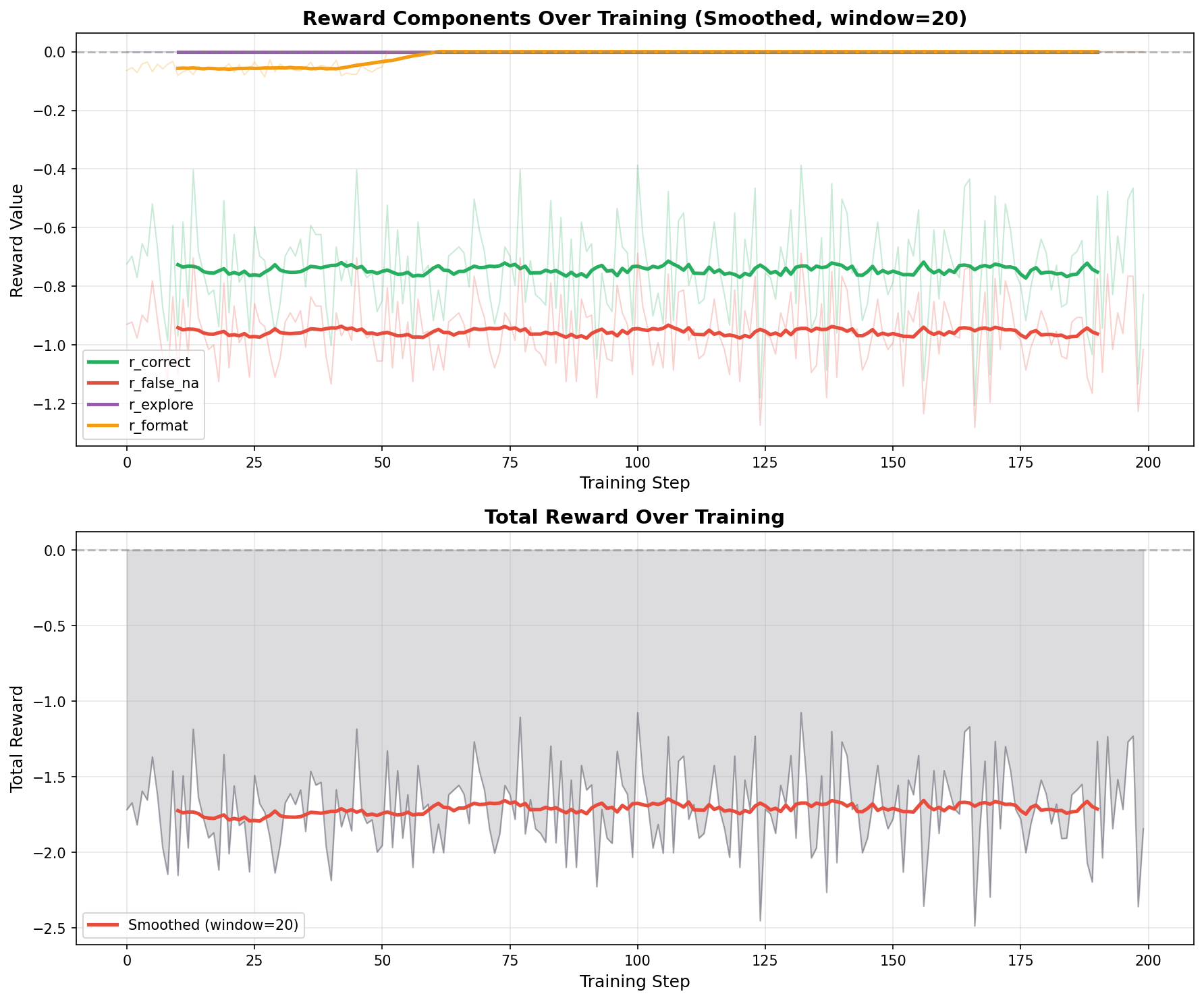
Hard-Only (2 sets - worst)
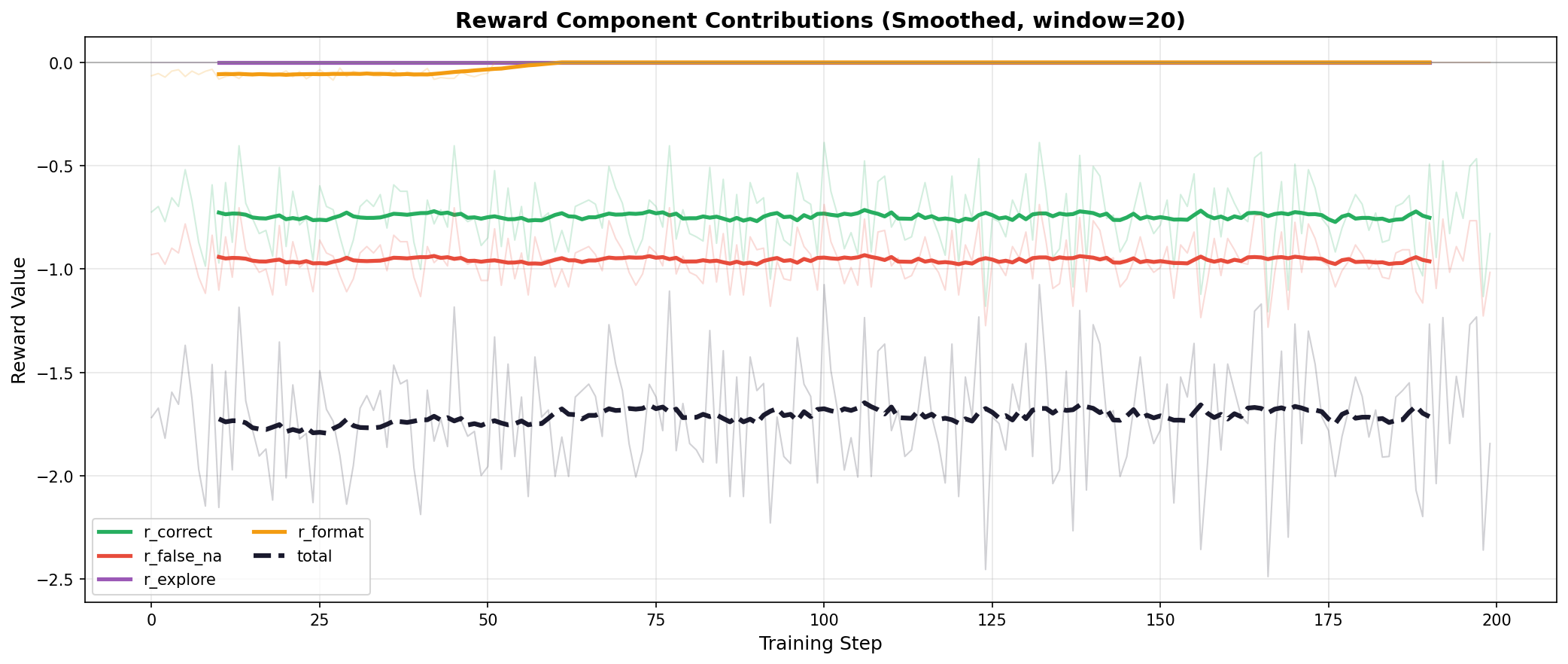
Per Reward Component
Breaking down the reward signal into its constituent components shows how each configuration balances accuracy, exploration, and format compliance.
Hard-Weighted, all 3 datasets (Best)
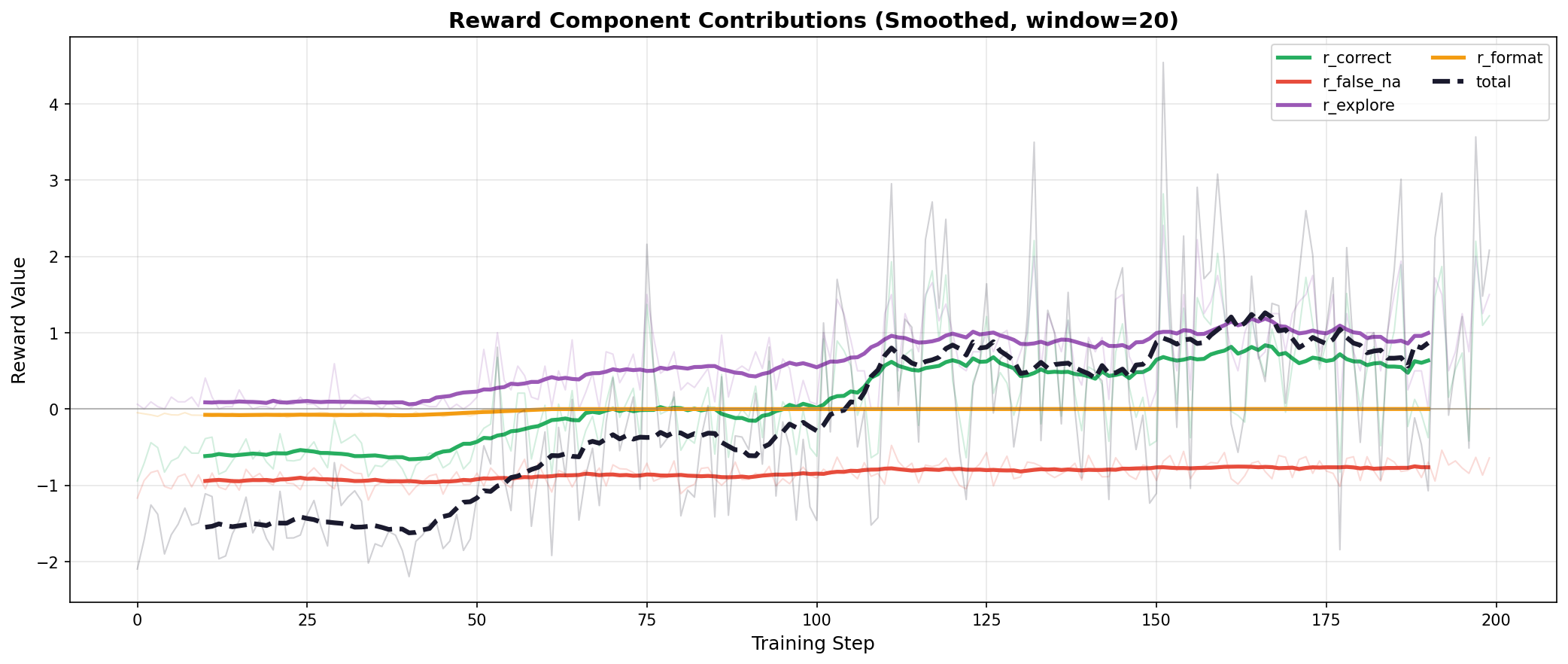
Balanced, all 3 datasets (Worse)
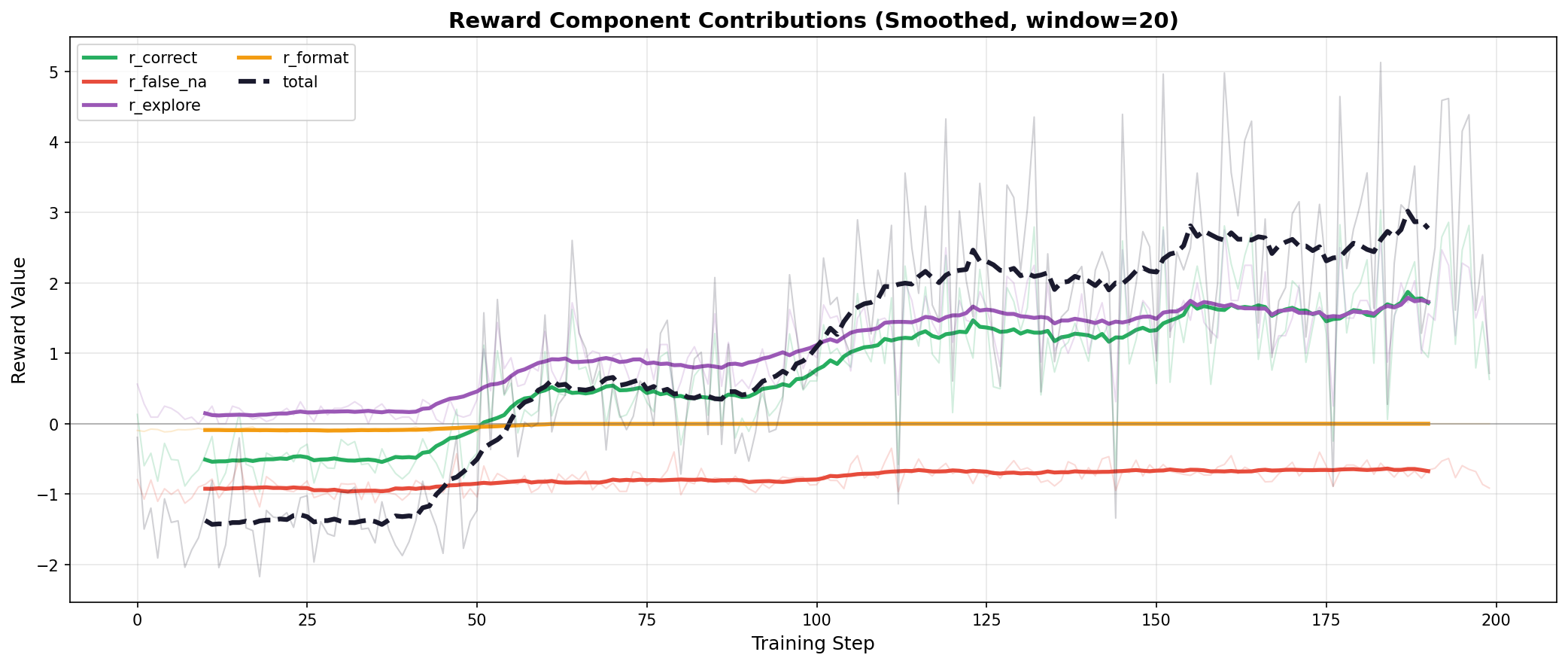
Hard-Only (2 Sets)
Results: Training Dataset Distribution and Self-Aware Generalization
Experimental Configurations
| Configuration | Training Distribution | Description |
|---|---|---|
| Hard-Weighted (Best) | ClimateFEVER + VitaminC heavy, FEVER light | Skewed toward difficult examples with easy anchors |
| Balanced (Worse) | Equal split across all 3 datasets | Uniform representation |
| Hard-Only (2 Sets) | ClimateFEVER + VitaminC only | No easy examples |
Training Dynamics: Reward Curves
| Metric | Hard-Weighted (Best) | Balanced (Worse) | Hard-Only (2 Sets) |
|---|---|---|---|
| Final Total Reward | +1.0 | +2.8 | -1.7 |
| r_explore (final) | +1.0 | +1.5 | ~0 |
| r_correct trajectory | Gradual climb | Steep climb | Flat (no learning) |
| Variance | Moderate | High | High |
Hard-Weighted (Best): The reward curve shows steady, moderate growth. r_correct climbs gradually from -0.6 to +0.8, and r_explore increases to +1.0. The total reward crosses zero around step 75 and stabilizes at +1.0. This gradual trajectory indicates stable learning without over-optimization.
Balanced (Worse): Despite achieving the highest training rewards (+2.8 total), the steep climb in r_correct (+1.8) and r_explore (+1.5) suggests aggressive optimization on the training distribution. The model learns to maximize the reward signal but overfits to the balanced mixture rather than developing robust cross-domain self-awareness.
Hard-Only (2 Sets): Complete training failure. All reward components remain flat throughout 200 steps—r_explore stays at zero, indicating the model never attempts PASS/FAIL predictions. The total reward is stuck at -1.7, demonstrating NA collapse where the model defaults to the safe neutral prediction.
Evaluation Performance (Relative Gains from Baseline)
Hard-Weighted (Best) - Skewed toward hard examples for all 3 datasets
| Dataset | Accuracy | Macro F1 | NA_f1 | NA_recall |
|---|---|---|---|---|
| FEVER | +18.4% ✅ | +0.34 ✅ | +0.01 ❌ | +0.01 ✅ |
| VitaminC | +20.7% ✅ | +0.30 ✅ | +0.16 ✅ | +0.14 ✅ |
| ClimateFEVER | +23.4% ✅ | +0.34 ✅ | +0.37 ✅ | +0.31 ✅ |
Balanced (Worse) - Equal split across 3 datasets
| Dataset | Accuracy | Macro F1 | NA_f1 | NA_recall |
|---|---|---|---|---|
| FEVER | +19.6% ✅ | +0.35 ✅ | +0.03 ✅ | +0.01 ✅ |
| VitaminC | +13.6% ✅ | +0.22 ✅ | -0.04 ❌ | -0.03 ❌ |
| ClimateFEVER | +13.5% ✅ | +0.22 ✅ | +0.02 ❌ | +0.01 ❌ |
Hard-Only (2 Sets) - No easy examples
| Dataset | Accuracy | Macro F1 | NA_f1 | NA_recall |
|---|---|---|---|---|
| FEVER | -3.2% ✅ | +0.03 ❌ | -0.17 ✅ | +0.01 ✅ |
| VitaminC | +27.1% ✅ | +0.31 ✅ | +0.36 ✅ | +0.57 ✅ |
| ClimateFEVER | +29.7% ✅ | +0.27 ✅ | +0.60 ✅ | +0.89 ✅ |
Legend:
- ✅ = Statistically significant (p < 0.01)
- ❌ = Not statistically significant
- Bold = Key metrics supporting conclusion
Key Findings
1. Hard-Weighted Distribution Yields Best Overall Generalization
The configuration with more hard examples (ClimateFEVER + VitaminC) than easy (FEVER) achieves the most balanced performance across all datasets. Critically, NA_f1 and NA_recall improvements are statistically significant on both hard datasets (VitaminC: 0.50/0.36, ClimateFEVER: 0.47/0.36). The model learns to recognize genuine uncertainty because it encountered sufficient difficult cases during training.
2. Equal Distribution Overfits to Easy Examples
The balanced configuration achieves the highest training rewards (+2.8) and best FEVER performance (95.5%), but fails to learn calibrated NA predictions on hard datasets. NA_f1 and NA_recall improvements are not statistically significant on VitaminC (0.31/0.19) or ClimateFEVER (0.11/0.06). The model optimizes aggressively for the training signal but doesn’t develop robust self-awareness for challenging domains.
3. Hard-Only Training Breaks Easy Domain Performance
Excluding easy examples entirely causes training collapse—the reward curves show no learning. While evaluation shows strong hard-dataset accuracy (VitaminC 63.2%, ClimateFEVER 57.4%), the model regresses on FEVER (72.7%, down from 75.9% baseline).
Summary Table
| Configuration | Training Signal | Easy (FEVER) | Hard Datasets | NA Calibration |
|---|---|---|---|---|
| Hard-Weighted (all 3 datasets) | Moderate (+1.0) | Strong (94.3%) | Best (54.1% avg) | Significant |
| Balanced (all 3 datasets) | Highest (+2.8) | Best (95.5%) | Worst (45.5% avg) | Not significant |
| Hard-Only (2 datasets, without fever) | Failed (-1.7) | Regressed (72.7%) | Good (60.3% avg) | N/A |
Conclusion
These results directly support the claim that diverse training datasets improve generalization, with harder examples requiring stronger representation than easier ones to effectively shift model behavior. The hard-weighted configuration outperforms the balanced split on challenging domains while maintaining strong easy-domain performance. However, training exclusively on difficult examples fails to transfer to simpler domains—the hard-only configuration shows this failure dramatically, with FEVER accuracy regressing below baseline.
The optimal strategy for self-aware fact verification is to weight training data toward hard examples while retaining easy examples as learning anchors. This enables the model to develop calibrated uncertainty estimation across the full difficulty spectrum, rather than over-optimizing for one end of the distribution.
References
[1] Kadavath et al. “Language Models (Mostly) Know What They Know.” 2022. arXiv:2207.05221
[2] Xiong et al. “Can LLMs Express Their Uncertainty?” 2023. arXiv:2305.18153
[3] Schuster et al. “Get Your Vitamin C! Robust Fact Verification with Contrastive Evidence.” NAACL 2021. ACL Anthology. VitaminC GitHub. github.com/TalSchuster/VitaminC
[4] Aly et al. “FEVEROUS: Fact Extraction and VERification Over Unstructured and Structured Information.” 2021. arXiv:2106.05707
[5] DeepSeek-AI. “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.” 2025. arXiv:2501.12948